Here are my high-level notes / abridged summary of memory management and virtual memory, mostly (completely) from Operating Systems: Three Easy Pieces.
Background
You may already know about pages and how virtual memory is managed today, but before talking about that, let’s look at some context (or skip ahead).
Address Spaces
At the start of time, only one program would run on a machine, on physical memory alongside the OS (which was just some functions, basically a library).
Later, CPUs became time shared and multiple programs started being executed concurrently. However, it is too expensive to give the current program all the the physical memory, especially with the over head of saving and restoring a process’s memory to and from disk with each context switch. Memory has to be space shared.
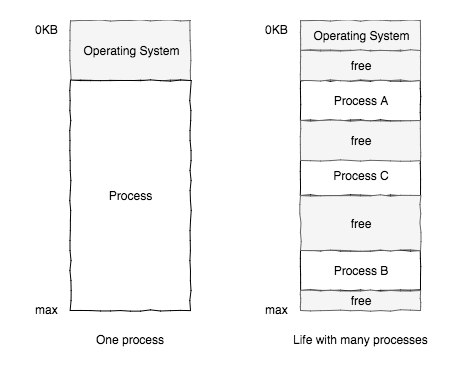
Sharing memory. We’ll see later this is more like using base and bounds registers, not paging
Virtual memory refers to how the OS manages multiple processes sharing physical memory. Each process gets its own virtual address space, which gives the process the illusion of having all of the physical memory. The OS manages mapping these address spaces to the shared physical memory.
Ideally this would offer:
- transparency: programs act as if they had direct physical memory
- efficiency: time and space overhead
- protection: isolation between processes
The OS is responsible for managing and accounting for memory. For example maintaining what memory is free vs used, what blocks are owned by what process, and responding to requests to get or free memory.
Address Translation
Every address you see in a program is virtual.
A virtual address points to a location in a process’s address space. The hardware must transform each memory access by converting the virtual address into the corresponding physical address (on the memory manage unit, MMU, part of the CPU).
The OS intervenes to maintain control over how memory is used.
Base and Bounds
Problem: Given multiple address spaces in memory like the first diagram, how does hardware know where the OS has physically located a process’s address space.
Idea: OS manages two registers: a base (start) and bounds (end or limit).
Segmentation
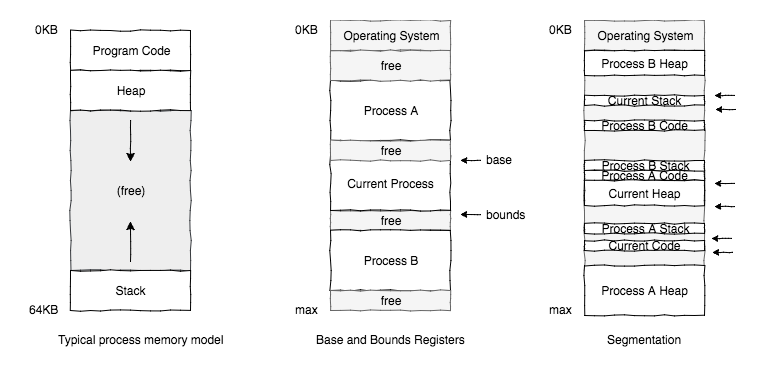
Base and Bounds Registers and Segmentation
Problem: base and bounds can lead to terrible internal fragmentation with unallocated space between the stack and heap.
- internal fragmentation: wasted space within an a chunk
- external fragmentation: wasted space between chunks
Idea: Instead, maintain one base and bounds pair per “logical segment” of the address space (code, stack heap)
This also enables shared memory between processes, for example code sharing. Protection bits are added (e.g. read-only for shared memory).
Paging
Problem: Unfortunately with all these variable-sized segments, there can be bad external fragmentation. The OS has to search available free blocks, and may have to fail a request for memory if no contiguous free block exists, even if there is enough spread between segments.
Managing free space is simple with fixed-sized units. Fixed-sized units don’t suffer from external fragmentation and allocation just returns the next free block.
This is what paging is: divide the virtual address space into fixed size units called pages. Similarly divide physical memory into fixed size slots called page frames (each page frame can hold a single page).
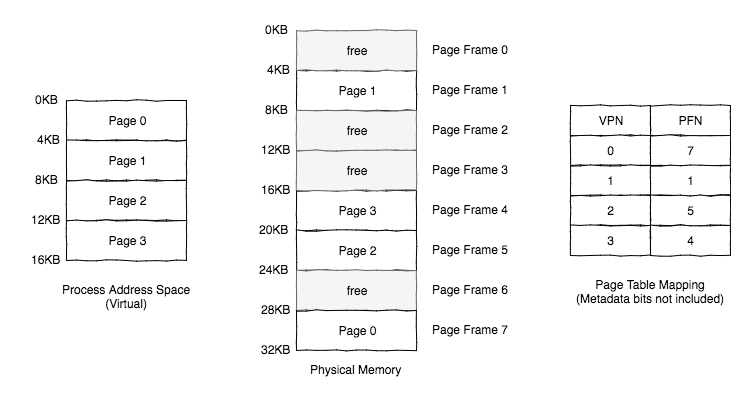
Illustration of pages in the address space, and how they map to physical page frames.
Page Tables
A page table stores the mapping from virtual page number (VPN) to physical frame/page number (PFN/PPN) and metadata. A example simple linear page table is an array, where indexing the array with a VPN gets the appropriate page table entry (PTE).
A PTE will have PFN and some additional metadata, e.g. we generally want:
- valid bit: e.g. unused/unallocated space in middle is marked invalid
- protection bits: read/write/executable
- present bit: if it’s present in memory or swapped out
- dirty bit: modified since memory
- reference bit: track if accessed, useful for page replacement
To translate a virtual address into physical memory, generally the highest order bits are used as the VPN and the remaining the offset into the page. By indexing into the page table, the address can be computed (e.g. PFN * page size + offset).
Page tables can be very large, too large for the processor so they get stored in memory.
For example, a 32-bit address space with 4KB pages has 2^20 virtual pages (2^32/2^12). This means we need 20 bits to index the VPN, or 2^20 translations. At 4 bytes per page table entry, this is 4MB per page table per process.
Review of the terms:
- Virtual Page Number (VPN): id of virtual page
- Physical Page/Frame Number (PPN/PFN): id of physical page (typically used as PFN)
- Page Table: map from VPN to PFN
- Page Table Entry (PTE): entry in page table
TLBs: Faster Page Translations
Problem: page tables are in memory, so on every address translation, hardware has to make an extra memory reference to get the VPN to PFN conversion. This is very expensive.
Idea: cache virtual-to-physical page translations. This is called the translation-lookaside buffer (TLB) (instead of address-translation cache for some reason)
TLB Entry
A TLB entry consists of: VPN, PPN and other bits (e.g. valid, protection, dirty bits).
Note valid bit is separate from the PTE valid bit:
- Invalid PTE: page has not been allocated
- Invalid TLB entry: not a valid translation (might invalidate on boot)
The TLB is an example of a fully associative cache: both VPN and PPN are present. A lookup searches the entire cache in parallel.
TLB Algorithm
When translating, the page is either in cache or not:
- TLB hit: get VPN to PFN, compute translation
- TLB miss: get PTE from memory (expensive), update TLB, compute translation
TLBs are a good example of locality in data:
- spatial locality: nearby data likely used as well (e.g. iterating over an array)
- temporal locality: recently used likely used again
Either hardware or the OS could handle a TLB miss. If the hardware handles it, it has to know about the location and format of the page table and entry (less flexible). Otherwise the hardware could raise an exception to a trap handler.
TLB and Context switches
Problem: if we switch processes, we need to be sure a cached translation does not convert the new process’s addresses to physical memory owned by another process. Flushing the TLB on context switch is possible but expensive
Idea: address space identifier: Add a field in the TLB entry to label the owner of the translation. Memory requests now need to communicate the requesting process
Other
TLB Coverage: if a program accesses more pages than can fit in the TLB, performance suffers heavily (TLB thrashes). Possible solution, larger pages, which is common in databases because large randomly accessed data structures in memory.
Paging: Saving Space
Problem: Even page tables can be too big and consume too much memory.
Multi-level page tables
Idea: Most pages in an address space are invalid, so try to reduce memory used for these. If we have an entire page sized block of invalid page table entries, don’t allocate that page of the page table. This is a multi-level page table
We can track with a new structure called a Page Directory. This is just another name for having a page table which points to the page with the next level of the page table, that has the relevant PTE.
This approach is much more compact, but slower on a TLB miss (at least another level of lookups). Hey more space vs time tradeoffs.
What if page directory gets too big? Add another level!
Larger Pages
Idea: Bigger pages, but this leads to internal fragmentation, so most pages end up using 4KB (x86) or 8KB. However, Huge pages are an option though, with 1MB or 1GB page sizes for example.
Inverted page tables
Some systems like the PowerPC store an index of every PFN to the VPN currently stored, rather than a mapping from VPN to PFN. Also compact, but finding a page is a search (can use hash table to speed up). This seems less common.
Swap
Finally, we can reserve a swap space on disk to extend memory. The OS can then offload (swap) unneeded or excess pages to disk.
This can be tracked with a present bit in the PTE which is set if the page is in memory. If it is not set, this is a page fault and the OS needs to swap the page into memory (note this is expensive because of the disk I/O).
Generally, the OS tries to keep a small amount of memory free proactively. When less than a low watermark of pages are free, a background thread (swap/page daemon) runs, evicting until a high watermark of pages are available. By doing so in batch, it can be more efficient (in I/O). Because swapping is expensive, the page replacement policy is important.