I’ve been wondering about what performant server applications and frameworks (Nginx, Apache HTTP Server, Netty, Nodejs, etc.) are doing to make them orders of magnitude better than whatever naive implementation I would have cobbled together.
Turns out they do a lot (nobody is surprised) and learning about it is like going through a history book of scalability and the Linux kernel. But let’s just start with one thing I’ve found pretty important: IO.
What does a high performance server care about
High performance servers deal with serving and multiplexing connections with as little overhead as possible. This usually ends up being the problem of scaling to lots of concurrent connections, without negatively affecting the performance of serving any single request (e.g. latency) and/or the server choking. Of course there will always be plenty of application work, but the server performance is about serving the connections.
Why concurrent connections? In the case of short lived requests it’s not as big of an issue. But as requests get longer, in-flight requests stack up. For example, if a server is handling 1000 requests per second, and each takes 10 seconds, at steady state the server is dealing with 10,000 concurrent requests. The C10K problem is worth a read.
There’s also just general performance stuff, like it’d be nice if the server spent it’s time doing meaningful work, taking advantage of available cores. High-Performance Server Architecture also goes over the Four Horsemen of Poor Performance: Data copies, Context switches, Memory allocation, and Lock contention.
IO
IO turns out to be a pretty fundamental part of serving requests. There’s reading request data, writing response data and maybe also some disk IO (maybe for serving static files?) and network calls to application servers.
Most example networking code looks like this:
for conn in open_connections:
read(conn)
Notably, the system call read blocks by default, so if a connection hasn’t written any data, our program is stuck waiting, unable to serve other connections. Same issue if we’re waiting on disk IO, writing responses, etc. We need a way of serving requests despite long IO calls.
Lucky for us, there are five models of handling IO.
But before looking at them, it’s useful to think of IO as two stages:
- no data / data in controller -> data becomes available to the kernel
- data in kernel -> data in our application’s memory
Ok, the five models:
1. Blocking
The system call does not return until data has arrived and been copied into our application. Sort of made feasible in a multithreaded environment, where meaningful work can occur even if some threads are blocked.
2. Nonblocking
Instead of blocking, the system calls can immediately return EWOULDBLOCK if data is not available. This means we can now loop through all connections and serve them as needed, but if nothing is available we end up polling (busy waiting) and burning through CPU.
3. I/O Multiplexing: Select/poll/epoll/kqueue
Rather than work on just one file descriptor at a time, we might want a method to monitor changes on lots of file descriptors. These are all just different polling methods/iterations for doing that.
select lets you pass in a list of file descriptors and it returns the status on each FD. It has some pretty big performance limitations (e.g. returns status of all FDs and you have to loop through to find what you’re interested in. Limited by FD_SETSIZE which is 1024 in Linux).
poll select minus the big problems, works well up to a few thousand connections and might be good enough for small use cases.
epoll (linux), kqueue (bsd) the recommended polling option. A bit of extra implementation complexity but scales much better.
Interestingly these offer a level-triggered” where they return all file descriptor events as long as they are true (e.g. available to read) and an “edge-triggered” mode where they only return when a change happens (something became available to read).
libevent wraps these in a uniform API so you can just use the best that’s available
IO Completion Ports I believe is the polling method on Windows
Also useful to know: these statuses are only hints. You should still mark the sockets as nonblocking so you don’t end up blocking if the socket is no longer ready.
Here’s a more in depth comparison of select/poll/epoll I liked.
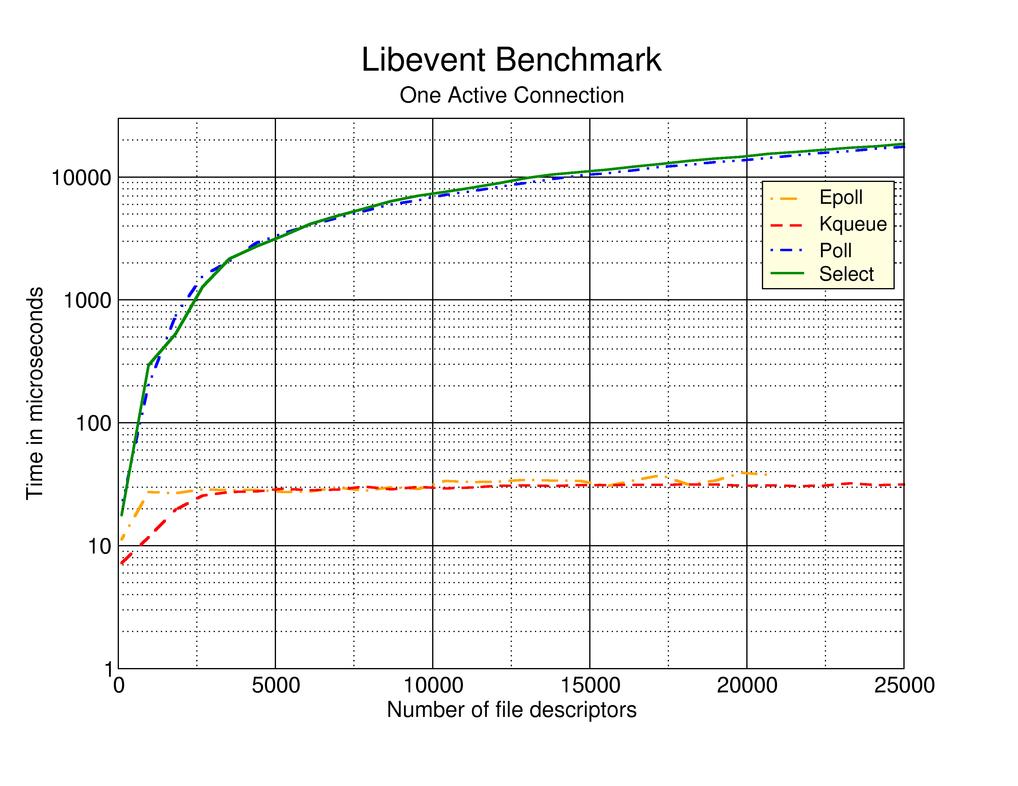
Comparison of how the polling methods scale (from libevent)
4. Signals (SIGIO)
Instead of checking on the status of the file, we can ask the kernel to send a signal when data is available.
I haven’t found any servers using signals heavily. Some complain about managing signals across threads, and it seems to me like a difficult model to control your application through interrupts but maybe I’m not familiar enough with signals.
5. (4.5) POSIX AIO
Applications initiate I/O operations, and get notified when they are complete (through signals). Like SIGIO but it’s once the data has been moved to the application buffer.
AIO seems like a nuanced subject, but from what I’ve found it seems unnecessary and unsupported for sockets and matters more for disk IO (which still comes up in servers, but not for handling connections).
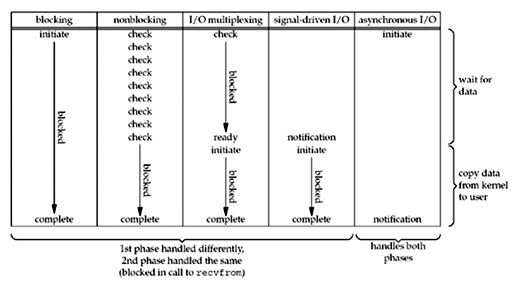
Comparison of IO models from Unix Network Programming
IO & Server Architecture
IO strategy (and parallelization strategy) drive server architecture. The most common choices are:
A Thread per connection
One way of scaling up blocking IO is to spawn a thread per connection, and just let the threads block on reads and writes. While they wait, other threads can work.
This model is conceptually simple, particularly because each connection is isolated (other than the whole thread shared memory thing). But the number of threads becomes a bottleneck as concurrent connections increases. Context switches add up and even the stack size of threads can become a memory limitation.
You could try to get around this with a finite thread pool, but then if you’re running at capacity, there will be connections queued while threads are waiting on IO.
Apache uses this method. It has a process per connection and a thread per connection mode. Both modes keep a pool around (preforking) and grow it if there are too many connections.
Event loops and polling
Here we multiplex connections by having a single thread that waits on a polling method (poll, epoll) for events from many connections. As events come through (e.g a new connection, data available, response from downstream), the server calls the appropriate event handler. One method of scaling this up to multiple cores is by just creating an entire event loop process per core and divide incoming load (Nginx does this).
This has been the architecture of choice for scaling up to high concurrent connections. There is a much lighter overhead per connection, which becomes critical past a few thousand threads. This comes at the cost of impelementation complexity (for example, tracking the state of a connections is harder, event handlers have to be nonblocking).
Nginx, NodeJS, Netty all use an event loop internally.